
mono domains (or mono for short) is a domain search engine/price comparison site that I built during the month of March 2023.
The general idea behind mono is to provide the information of services such as TLD-List, with the UX and ease of use of something like Domainr.
Behind the scenes, mono is made up of three main parts:
- A scraping routine to fetch all the prices from each registrar, made in NodeJS
- An API used to serve said pricing information aswell as search results, made in PHP
- A front end used to show all that information to the user, made in Nuxt 3
Let's talk about each of those a little bit:
getting pricing info
The first task when it came to making this website was getting all of the pricing information for each extension on each registrar.
My original hope was that registrars would offer some sort of easy to use API to get all of their pricing information (naive, I know 😄).
Unsurprisingly most registrars didn't offer any API at all, and the ones that did included a lot of information that wasn't of particular interest to me.
So, without much messing about, I moved on to plan B.
Web Scraping
While I know web scraping can be a bit of a contentious topic, it was the second best option in my head as to how to solve this problem.
I started out writing a simple script using Playwright and cheerio that allowed me to scrape pricing from a single registrar and store it in a MySQL database.
Once that was all working fine I could just split out the scraping routine itself into its own class with consistent inputs and outputs, which then made it dead easy to incorporate similar routines for other registrars.
Before long I had a fully modular system that made adding new registrars as simple as writing a quick scraping script. Great!
With that out of the way, we can move on to the next bit.
creating an api
As I briefly mentioned before, I was storing all the pricing information I was gathering in a MySQL database.
So now I had a table of a few thousand rows of pricing information that I had to deliver to the user, which meant I had to make some sort of API.
You might be wondering why I chose to use a MySQL database over something a bit better suited to Node (like MongoDB).
The answer is simple, it's because I was planning to build the API using everyone's favourite language...
✨PHP✨
Why PHP? Two main reasons:
- I hadn't done any real PHP development in a while, and as it was the first web language I learned I was missing it 😢
- Using PHP meant I could just use an out of the box LAMP/LEMP setup to host, rather than having to mess about getting something going myself
Since this API is dead simple, I didn't bother using any super fancy frameworks like Symfony or Laravel. It uses this routing library by Bramus as a backbone, then everything else is made in vanilla PHP.
With that out of the way, let's go through the three main functions of the API:
Pricing Information
This is probably the simplest of the three functions in that all it does is fetch information from the aforementioned database.
So, for example, if the user visits the /extension/.com endpoint they'll be given all of the pricing information in the database relating to .com.
Whois Queries
One thing that mono does when you perform a search is it tells you whether or not a domain is available or not. The only concrete way to gather this information is by sending a request to the registry's whois server.
My original idea was to use a third party API to do this for me. However it was difficult to find one that wasn't either super limited or expensive, so I decided to make my own instead.
Luckily for me, a developer called Sergey Sedyshev created an amazing PHP Whois library that basically takes care of everything.
The only real issue is that some of the more obscure extensions may have strict registrarion rules which result in whois query errors. However, that's nothing that a little error message can't solve.

Domain hack searches
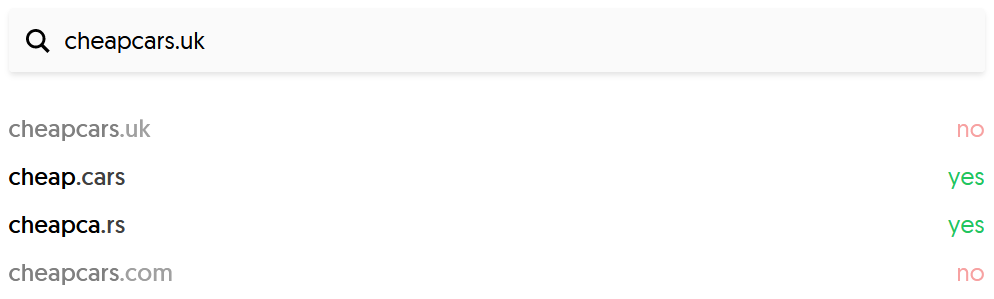
For those unaware, a domain hack is where you include the domain extension as part of the domain name that you want to register.
As an example, let's take the phrase 'cheapcars'. Two domain hacks for this phrase would be:
- cheap.cars - using the generic .cars domain extension
- cheapca.rs - using the Serbian .rs domain extension
I imagine there are several ways you can go about looking for domain hacks, however here's the process that mono uses. We'll use 'cheapcars' as an example again.
- Get the last two letters of the search term (so 'rs' in this case)
- Find all extensions in the database that also end in those letters (.builders, .cars, .flowers, .rs etc.)
- Loop through the extensions returned from the database and exclude any that don't fit into the end of the search term, like below:
foreach ($potentialExtensions as $extension) { $flattenedExtension = str_replace('.', '', $extension); $extensionPosition = strrpos($domain, $flattenedExtension); if ($extensionPosition !== false // If the extension is in the domain, && $extensionPosition > 0 // Isn't right at the start && $extensionPosition + strlen($flattenedExtension) === strlen($domain)) { // And is at the end $hackedDomain = substr($domain, 0, $extensionPosition); // If the resulting domain is invalid, we shouldn't add it to the results if (!$domainHelper->isValidDomain($hackedDomain)) { continue; } // Gather further information about extension, etc... }}This process will then leave us with the two extensions listed above, .cars and .rs.
It should be noted that doing the search this way excludes partial domain hacks (such as cheap.ca, which could then have a subdirectory to create cheap.ca/rs). However, since hacks like that are kinda confusing anyway, I don't think it's really that much of a loss.
There is a bit more that goes into the search than that, such as doing multiple passes and detecting included extensions, but that's the most complex part.
And that's about it for the API 🎉 Let's move on to the front end.
the front end
Before even starting to build mono, I had two things that I wanted to incorporate into the site:
- I wanted the colour scheme to be mostly monochromatic (hence the name!)
- I wanted to use the geomanist font from atipo foundry, since I bought it a while ago and liked it.
With those things in mind (and no actual design or plan 😅) I set off building the front end.
I decided to go with ol' faithful Nuxt as the framework of the site, with the intention to generate it statically and host with something like Netlify.
For styling, I opted to try out Tailwind CSS for this project since it was relatively simple and gave me a chance to dip my toes in. For what it's worth, I rather enjoyed using it and will probably use it again.
Finally, to give the site a bit more ✨pizazz✨ without any more actual effort I added AutoAnimate into the mix, which is an awesome library that I definitely will be using again!
Since the front end is essentially just displaying the information sent from the API, which we've already talked about, there's not too much else to add here.
Let's talk about hosting.
hosting
Since this is a full stack application let's split this up into two different sections to make things clearer.
Back end
As I mentioned earlier on, part of the reason that I chose to use PHP to build the API for mono is to make things easier when it came to setting up hosting.
I personally chose to use the LEMP stack simply due to having recent experience working with NGINX based servers.
From there setting up the API server was as simple as spinning up a VPS with Vultr with their one-click LEMP app, then using git to transfer over the code.
Next up was setting up the scraping script.
Luckily, since this bit wasn't public facing I didn't have to make any special config changes in NGINX to get it working.
Instead I just installed NodeJS and npm using nvm, installed the dependencies, linked up the database and hey presto we're scraping! 🪄
From there I put together a small bash script to run the scraper and log the output to a file:
#!/bin/bashsource ~/.nvm/nvm.shnode ~/mono-scraper/app.js 2>&1 | tee /var/log/scraper/$(date +%Y%m%d-%H%M).logAnd set up a cron job to run that script twice a day. Sorted!
Front end
Hey, remember how I said that I was going to host this using Netlify? Well, that didn't really pan out.
The issue came in that mono creates a new page for every extension that is in it's database (by design).
This sounds good, until you realize that for every full build of the site you're going to be generating 2,000+ pages.
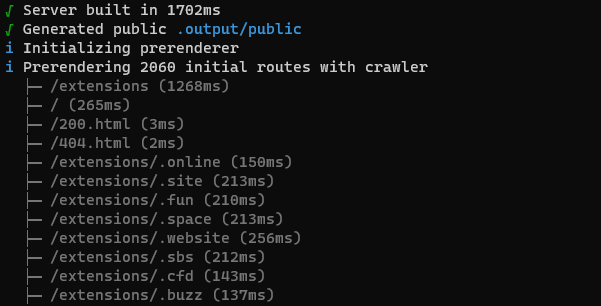
While this would still be possible using Netlify, what I found after some napkin maths is that doing so would basically eat up all of my build minutes every month.
This would mean my other sites (like this one!) wouldn't be able to be built at all, which simply wouldn't do.
So, after looking at Netlify's premium pricing, I span up another LEMP VPS with Vultr to host the front end.
"But Josh," you ask, "If the site is generated statically, doesn't that mean that the information will be out of date once the scraping script runs again?"
No! 😄
Originally, my plan to prevent this from happening was to generate a new build hook with Netlify and call it at the end of the scraping procedure.
However, with having to provision my own server I didn't have access to fancy stuff like that out of the box. So I went for the next best thing.
At the end of the scraping procedure on the back end server there's a small script that SSHs into the front end server, runs the front end build script, then peaces out.
class FrontEndDeploymentHandler { async deployFrontEnd() { // Create a new connection to the FE server const ssh = new SSHConnection() const connection = await ssh.getConnection() // Run the build command const { stderr } = await connection.execCommand('source ~/.nvm/nvm.sh && npm run generate', { cwd: '/usr/share/nginx/html' }) if (stderr && !stderr.startsWith('WARN')) { throw new Error(stderr) } // Disconnect connection.dispose() }}Boom! 💥 Problem solved.
an update!
Hey! So it's currently few days after I originally wrote this article and things have changed with what I just said above.
Remember how I said that the build of the site would take so long that it'd eat up all my build minutes on Netlify? Well that's not entirely true anymore.
Turns out I was doing the site generation process in a fairly inefficient way.
To make a long story short, for each page that the site generated it'd make a call to the back end to fetch the information for each extension.
However, I realized that I was already fetching some of this information when generating a different page of the site (the extension listing page).
So I thought to myself:
"If I include all the information that I need in the extension listing page endpoint, could I then cache the result and use it to generate the other pages? And would that be quicker? 🤔"
Turns out, the answer to both of those questions is a big fat yes! 🥳
After taking a bit of time to implement these changes, I managed to take the build time (on my PC) down from ~4 minutes to less than 30 seconds!
And with that, I canned the front end server and switched it over to use Netlify instead (for free 🤑)
That's that really! There's still improvements to make to mono in the future, but I'm very happy with how this project has turned out so far.
If you wanna check out mono, you can find it at mono.domains.
Thanks for reading! 👋